
The release of powerful GPT models has thrust vector databases into the spotlight. These databases are poised to be a key technology in powering the next generation of AI applications, serving as a form of long-term memory and enabling more complex workflows for Large Language Model (LLM)-based systems.
The Evolving Need for Vector Databases
In the early days of the internet, data was largely structured, fitting neatly into the rows and columns of relational databases. These databases were designed for efficient storage and retrieval of data with predefined relationships.
However, the explosion of the internet led to a massive increase in unstructured data – text, images, videos, and more. Analyzing and extracting insights from this unstructured data proved challenging for traditional relational databases. Imagine trying to find a similar shirt from a collection of shirt images using only the raw pixel values – a task that would be virtually impossible for a relational database.
This is where vector databases come in. The rise of unstructured data has driven the development of machine learning models capable of understanding this data. A prime early example is word2vec, a Natural Language Processing (NLP) algorithm that employs neural networks to learn relationships between words. Word2vec transforms words into vectors – lists of floating-point numbers. The magic lies in the model’s training: vectors that are close to each other in the vector space represent words that share similar meanings, hence the term “embedding vectors.”
Understanding Vector Databases
A vector database is a specialized database designed to store, manage, and search data represented as vectors, also known as embeddings. Vectors are essentially arrays of floating-point numbers. The “dimension” of a vector refers to the number of elements in the array. A 100-dimensional vector, for example, is simply an array containing 100 floating-point numbers.
Traditional databases rely on exact matches or predefined criteria for querying data. Vector databases, on the other hand, use similarity metrics to find vectors that are most similar based on their semantic meaning or contextual relationships.
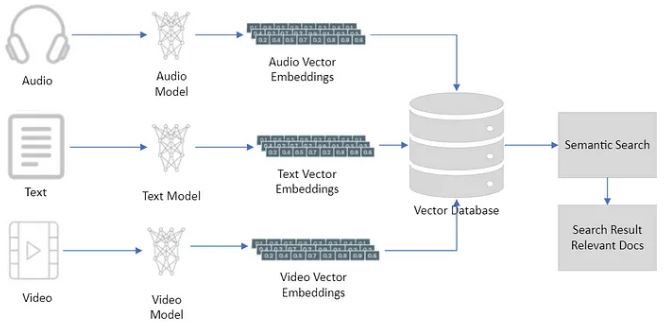
These vectors are created by applying an embedding function to raw data, such as text, images, audio, or video. The embedding function can utilize various techniques, including machine learning models, word embeddings, or feature extraction algorithms. The choice of embedding function depends on the type of data and the desired application.
Popular Vector Databases for AI Applications:
- Several vector databases are gaining traction for building AI-powered applications. Here are a few notable examples:
- Pinecone: A popular, commercially available vector database known for its developer-friendly interface, fully managed service, and scalability, making it suitable for high-performance vector search applications. They have recently secured significant funding, indicating strong market interest.
- Weaviate: A prominent open-source vector database that allows users to store data objects alongside vector embeddings generated by various machine learning models. It’s designed to scale efficiently, accommodating very large datasets.
- Milvus: An open-source vector database focused on providing a scalable platform for similarity search, enabling efficient retrieval of similar vectors from large collections.
- Chroma: An open-source embeddings database designed specifically for AI applications. It aims to provide developers with the tools to add memory and state to their AI systems, facilitating the development of more robust and aligned AI. They have recently received seed funding.
- Vespa: A comprehensive search engine that integrates vector database capabilities. It supports vector search (ANN), traditional keyword-based search, and structured data search within a single query. Its integration with machine learning model inference allows for real-time AI-powered data analysis. It is available as open source and cloud based service.
I hope this helps to understand the Vector databases.