
We are going to build custom ChatGPT using your own document library. We are going to take advantage of latest development in large language models (LLM) like OpenAI GPT-3, GTP-4.
There are 2 approaches to build question/answering system using LLM (Large language model).
1. Fine tune GPT
If you fine tune GPT, it will not limit your context to your data but, your data + data that GPT trained on. It can easily go out of context for answering your questions which are not relevant to you document. This will also require retraining the model for new data.
2. Semantic search + ChatGPT LLM (Large language model)
This approach will better fit to you question/answering system because it will give you context specific answers, easy to update your data with new information. In contrast to fine-tuning GPT requires re-training the model.
We are going to use Approach #2 here.
Followings libraries/framework will be used to build our question answering system.
- Langchain: It is a powerful library for developing LLM based applications.
- Pinecone: This will serve as vector database for storing your embedding vectors and performing semantic search.
- Streamlit: This will be used to deploy the app.
- OpenAI: LLM libraries from OpenAI.
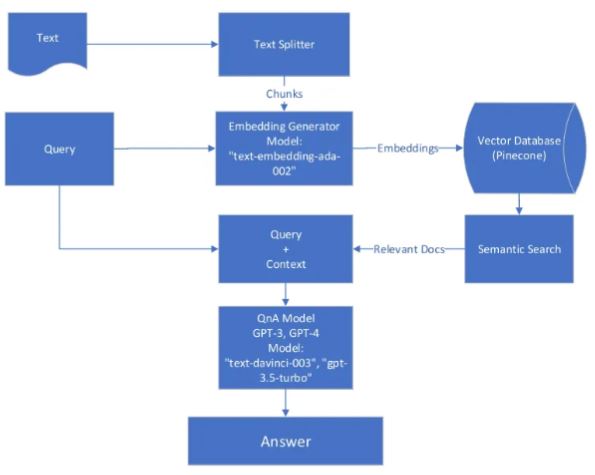
Follow through the code snippet below to create your own ChatGPT with your documents.
There are 2 components to this Question/Answering App.
1. Load your data embeddings vectors to Vector Database
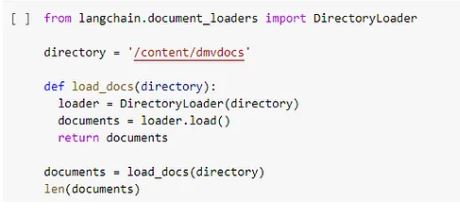
Get All the data files from folder. https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/directory_loader.html
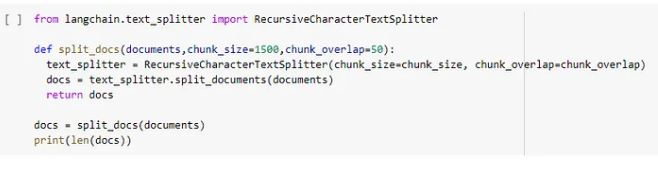
Split the text into chunks. https://python.langchain.com/en/latest/modules/indexes/text_splitters/getting_started.html
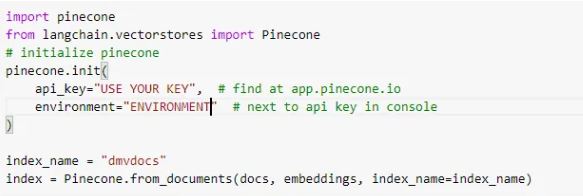
Generate embedding vectors for chunks.

Upload vectors to Vector database (here using pinecone) https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/pinecone.html
2. Querying your data from Vector Database, pass as context to LLM (GPT)
- Set your openAI Key
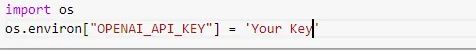
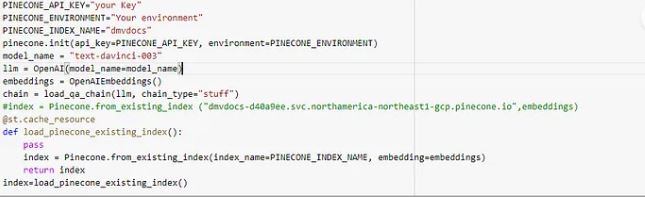
2. Initialize your pinecone Database with your index name (this have all your vecotrs).
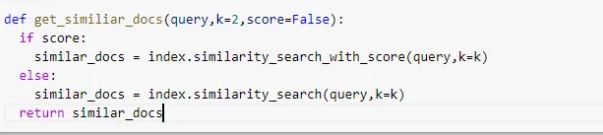
3. Query vector database, get the similar vectors (using similarity search), add these to your query vector and pass as context to GPT.
4. Get answer by passing above vectors to GPT.


You can use streamlit library to host to local or streamlit cloud or on EC2 instance.