
Imagine teaching a computer to distinguish between different types of fruit. Instead of programming specific rules for each fruit, you could show it numerous examples, allowing it to learn the distinguishing characteristics on its own. Neural networks operate on a similar principle, enabling them to discern patterns and relationships within data without explicit instructions.
A neural network represents a form of machine learning model inspired by the architecture of the human brain. It is fundamentally a system of interconnected processing units, often termed “neurons” or “nodes,” organized into distinct layers. These layers collaborate to identify structures and dependencies embedded within the data.
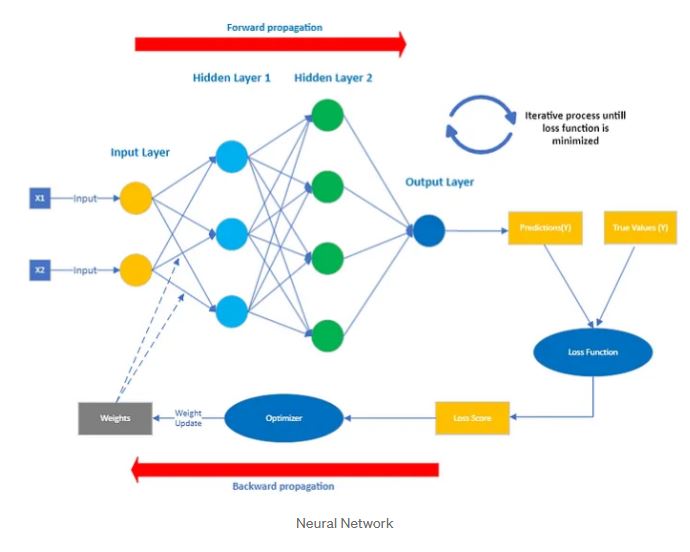
Understanding the Structure: Layers and Connections
Let’s examine the fundamental components of a typical neural network:
- Input Layer: This serves as the entry point for data. It receives the raw information that the network will analyze. In the fruit example, the input layer would receive information about a fruit’s color, size, and texture. For different data types, such as analyzing customer behavior, the input layer might take features like purchase history, demographics and website activity.
- Hidden Layers: These layers perform intricate calculations to extract meaningful features from the input data. The network can have multiple hidden layers, each focusing on different levels of abstraction. One layer may identify basic features, such as colors and shapes, while another combines them to recognize specific types of fruit.
- Output Layer: This generates the final result or prediction. In the fruit example, the output layer would produce the predicted probability of the input fruit being an apple or an orange. For customer behavior, it might output the predicted probability of the customer making a purchase in the next week.
Connections and Weights: The Essence of Learning
The neurons in each layer are interconnected, and these connections determine how information flows through the network. Each connection is assigned a “weight,” representing its strength or importance.
- A high weight indicates a strong influence on the next neuron.
- A low weight indicates a weak influence.
The training process involves adjusting these weights to optimize the network’s predictive capabilities.
The Learning Process: Unveiling Backpropagation
The training of a neural network involves finding the ideal set of weights that enable accurate predictions. This is done through an algorithm called “backpropagation”.
- Forward Propagation: Data flows from the input layer through the hidden layers to the output layer. Each neuron performs calculations and sends the result to the next layer, until a prediction is made.
- Error Calculation: The network’s prediction is compared to the actual answer, and the difference is measured as the “error”. A “loss function” quantifies this error, providing a single value that reflects the network’s performance.
- Backpropagation: The error signal is propagated backward through the network, adjusting the weights of connections to reduce the error. Neurons that contributed more to the error have their weights adjusted more significantly.
- Iteration: These steps are repeated many times with a large dataset of examples, improving the network’s accuracy with each iteration.
Why Are Neural Networks So Effective?
Neural networks excel at learning complex relationships and patterns within data, without needing manual feature engineering. This adaptability makes them valuable for a wide range of applications.
In Summary:
- Neural networks are inspired by the human brain and learn from data to make decisions.
- They comprise interconnected layers of processing units called neurons.
- Training adjusts the connection weights to minimize errors and improve accuracy.
- This enables the network to make predictions on new data.