
Try app at (Use your own Google Gemini API Key): https://mlprojects-text-to-sql.streamlit.app
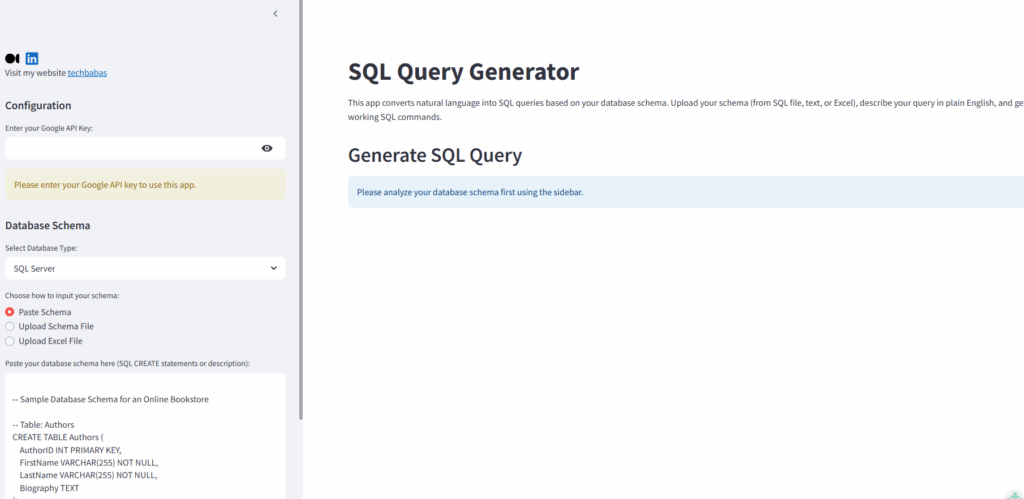
In today’s data-driven world, accessing and understanding data stored in relational databases is more crucial than ever. However, writing SQL queries can be a barrier to entry for many, especially those without a technical background. What if you could simply ask your database a question in plain English and get the results you need.
This blog post will guide you through the process of building a natural language to SQL query generator application using Streamlit, Agno, and the Google Gemini API. This powerful combination allows you to transform natural language queries into executable SQL commands, democratizing data access and analysis. We’ll explore the different components of the application, including schema analysis, query generation, validation, and results preview, all driven by AI agents.
Why These Technologies?
- Streamlit: A Python library that makes it incredibly easy to create interactive web applications for data science and machine learning. Its intuitive API allows you to build user interfaces with minimal code.
- Agno (Agent): A library that facilitates the creation and orchestration of language model agents. Agno simplifies the process of defining agent roles, providing prompts, and interacting with language models like Gemini.
- Google Gemini API: A cutting-edge large language model (LLM) from Google. Gemini’s ability to understand and generate human-like text makes it ideal for converting natural language into SQL.
Project Overview:
The application will:
- Accept Database Schema: Allow users to input their database schema via pasting SQL, uploading a file, or uploading an Excel sheet. If you have large database, you can extract schema information in excel sheet in below format: Example Excel structure for schema:
- table_name column_name data_type is_primary_key is_foreign_key
- Customers customer_id INT TRUE FALSE
- Customers customer_name VARCHAR(255) FALSE FALSE
- Orders order_id INT TRUE FALSE
- Orders customer_id INT FALSE TRUE
- table_name column_name data_type is_primary_key is_foreign_key
- Accept Natural Language Query: Provide a text area for users to describe their desired query in plain English.
- Generate SQL Query: Use Gemini to convert the natural language query and database schema into a valid SQL query.
- Validate SQL Query: Use Gemini to check the generated SQL for errors and compatibility with the schema.
- Preview Results: Use Gemini to generate sample results from the SQL query against the provided schema, allowing users to confirm their intent.
- Display Query History: Keep a record of previous queries for easy access and reuse.
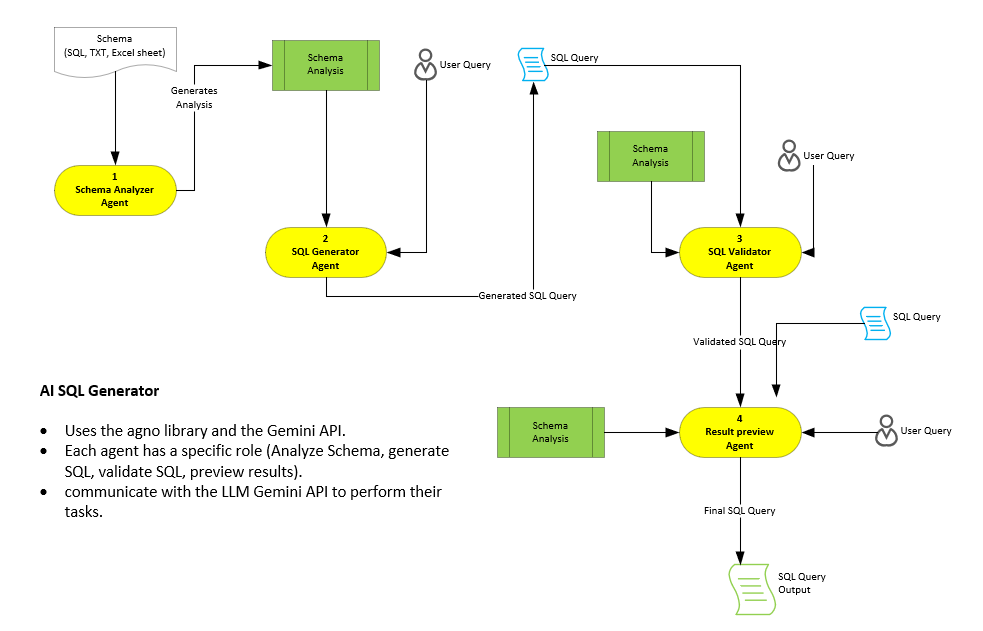
Architecture
Our application is built around the following architecture, it employs a modular architecture, consisting of several key components. These components are orchestrated within a Streamlit application that provides a clean user interface for interacting with the AI agents.
Key Components: Let’s dive into the key components of the application
- User Interface (Streamlit): Provides the front-end for user interaction. Users can input their database schema, natural language queries, and view the generated SQL and results.
- Schema Analyzer Agent: Analyzes the database schema to understand its structure, including tables, columns, data types, relationships, and constraints.
- SQL Generator Agent: Converts the user’s natural language query into an SQL query, using the analyzed schema as context.
- SQL Validator Agent: Validates the generated SQL query to ensure it’s syntactically correct and aligned with the schema and user’s intent.
- Results Preview Agent: Predicts the results of executing the generated SQL query against a hypothetical database with the given schema, providing a sample dataset.
- Refinement Loop: Iteratively refines the generated SQL query if the initial results don’t match the user’s intent, using feedback from the Results Preview Agent.
Architecture Overview:
1. Setting up the Environment and Dependencies:
First, ensure you have the necessary libraries installed:
pip install streamlit pandas agno python-dotenv openpyxl google-generativeai
You'll also need a Google Gemini API key. Obtain one from the Google Cloud Console and enter it directly into the Streamlit UI, as we will prompt for it.
Agents:
The agents are the heart of the application, leveraging Agno and Gemini to perform their respective tasks.
Each agent is initialized with a specific role description and the Gemini API key. The analyze_schema method constructs a prompt that instructs the agent to analyze the provided database schema and returns the analysis. Other agents (SQLGeneratorAgent, SQLValidatorAgent, ResultsPreviewAgent) follow a similar pattern with prompts tailored to their specific tasks.
Let’s examine each of the core components in detail:
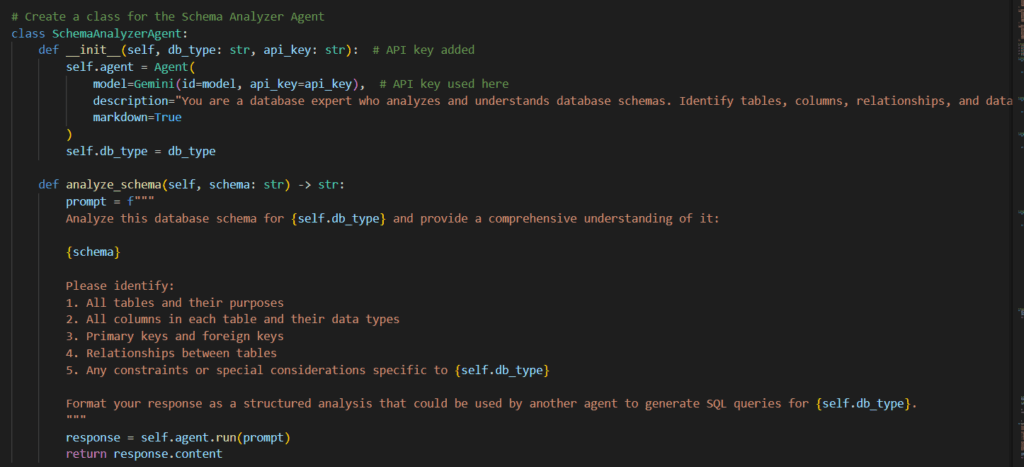
1. Schema Analyzer Agent (SchemaAnalyzerAgent)
This agent’s primary responsibility is to analyze the database schema provided by the user. It identifies tables, columns, relationships (primary keys, foreign keys), and data types. This comprehensive understanding is crucial for the subsequent stages of query generation and validation.
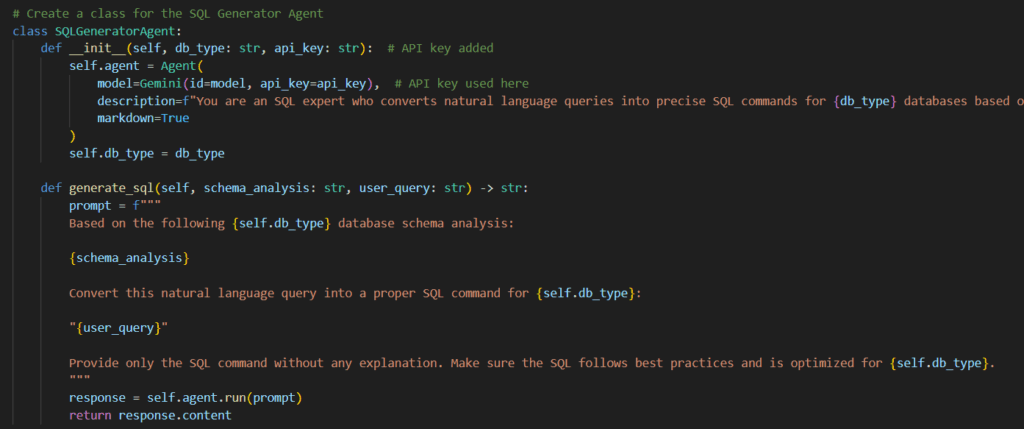
2. SQL Generator Agent (SQLGeneratorAgent)
This agent is responsible for translating the user’s natural language query into a corresponding SQL command. It leverages the schema analysis generated by the SchemaAnalyzerAgent to ensure the generated SQL is compatible with the database structure.
3. SQL Validator Agent (SQLValidatorAgent)
This agent plays a crucial role in ensuring the quality of the generated SQL. It validates the SQL for correctness, efficiency, and alignment with the user’s intent, comparing it against the database schema and the natural language query.

4. Refinement Loop:
The refine_sql_until_correct function orchestrates the iterative refinement of the SQL query:
This function takes the initial SQL query and the analyzed schema. It repeatedly calls the ResultsPreviewAgent to get feedback and, if necessary, re-engages the SQLGeneratorAgent to generate an improved query or uses the suggested_improved_query from the preview itself. The refinement loop continues until the generated results match the user’s intent or a maximum number of iterations is reached.
# Function to iteratively improve SQL query until it matches user intent
def refine_sql_until_correct(schema_analysis: str, user_query: str, initial_sql: str, db_type: str, api_key: str) -> Dict[str, Any]:
max_iterations = 3
current_sql = initial_sql
iteration_history = []
for i in range(max_iterations):
# Get results preview
previewer = ResultsPreviewerAgent(db_type, api_key) # API key passed
preview_results = previewer.preview_results(schema_analysis, user_query, current_sql)
# Store this iteration
iteration_history.append({
"iteration": i + 1,
"sql": current_sql,
"results": preview_results
})
if preview_results["matches_user_intent"]:
return {
"sql": current_sql,
"results": preview_results,
"iterations": i + 1,
"final": True,
"history": iteration_history
}
# If there's a suggested improvement, use it
if "suggested_improved_query" in preview_results and preview_results["suggested_improved_query"]:
current_sql = preview_results["suggested_improved_query"]
else:
# If no suggestion, try again with the generator
generator = SQLGeneratorAgent(db_type, api_key) # API key passed
feedback = f"Previous query didn't match user intent. Issues: {preview_results['explanation']}"
prompt = f"""
Based on the following {db_type} database schema analysis:
{schema_analysis}
Convert this natural language query into a proper SQL command for {db_type}:
"{user_query}"
Previous attempt:
```sql
{current_sql}
```
Feedback on previous attempt:
{feedback}
Provide only the improved SQL command without any explanation. The SQL should follow the syntax and best practices for {db_type}.
"""
current_sql = generator.agent.run(prompt).content
# Validate the new SQL
validator = SQLValidatorAgent(db_type, api_key) # API key passed
validation_result = validator.validate_sql(schema_analysis, user_query, current_sql)
if not validation_result["is_valid"]:
current_sql = validation_result["suggested_fix"]
# If we reached max iterations, return the last attempt
previewer = ResultsPreviewerAgent(db_type, api_key) # API key passed
final_preview = previewer.preview_results(schema_analysis, user_query, current_sql)
# Add last iteration to history
iteration_history.append({
"iteration": max_iterations,
"sql": current_sql,
"results": final_preview
})
return {
"sql": current_sql,
"results": final_preview,
"iterations": max_iterations,
"final": False,
"history": iteration_history
}
5. Putting it all Together:
The main execution flow in Streamlit involves:
- Getting the API key and database schema from the user.
- Analyzing the schema using the SchemaAnalyzerAgent.
- Getting the natural language query from the user.
- Generating, validating, and previewing the SQL query using the agents.
- Iteratively refining the query if needed.
- Displaying the final SQL and results to the user.
Key Takeaways
- Combining Streamlit, Agno, and Gemini provides a powerful and accessible way to build natural language to SQL query generators.
- Agent-based architecture simplifies the design and management of complex interactions with language models.
- The refinement loop enhances the accuracy and relevance of the generated SQL queries.
- Consider API usage costs and implement error handling for a robust application.
Next Steps
This blog post provides a solid foundation for building your own natural language to SQL query generator. Here are some potential next steps:
- Implement direct database connectivity: Allow users to execute the generated SQL queries against their actual databases and view the real results. Use caution when implementing database connectivity and sanitize SQL inputs.
- Enhance the UI: Add features like syntax highlighting, query history, and user authentication.
- Fine-tune the prompts: Experiment with different prompts to optimize the performance of the agents for specific database types and query patterns.
- Add support for more database types: Extend the application to handle different SQL queries.
By leveraging these technologies and building upon this foundation, you can create a valuable tool that empowers users to access and analyze data more effectively than ever before. This approach opens new possibilities for data-driven decision-making across various domains.
Very good
Awesome
Looks great, Anil! Can’t wait to try it
Awesome
Very good
Very good
Awesome
Good
Good
Awesome